
本文大约 3800 字,阅读大约需要 8 分钟
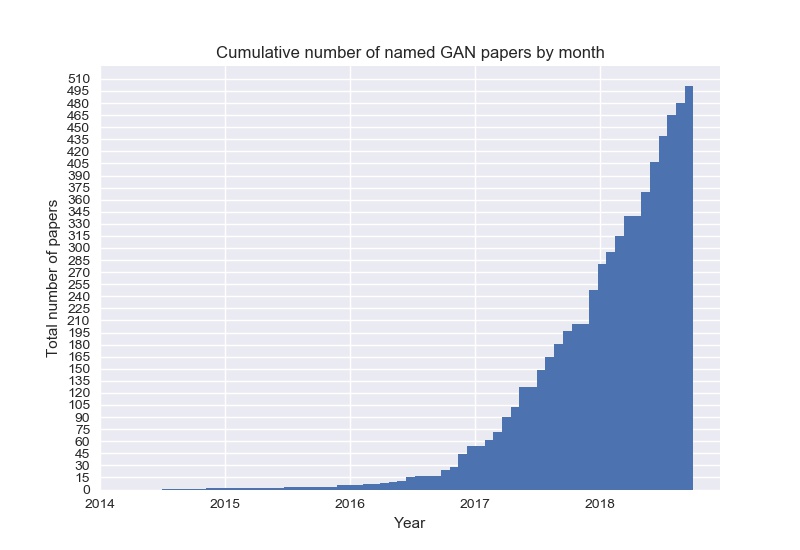
要说最近几年在深度学习领域最火的莫过于生成对抗网络,即 Generative Adversarial Networks(GANs)了。它是 Ian Goodfellow 在 2014 年发表的,也是这四年来出现的各种 GAN 的变种的开山鼻祖了,下图表示这四年来有关 GAN 的论文的每个月发表数量,可以看出在 2014 年提出后到 2016 年相关的论文是比较少的,但是从 2016 年,或者是 2017 年到今年这两年的时间,相关的论文是真的呈现井喷式增长。
那么,GAN 究竟是什么呢,它为何会成为这几年这么火的一个研究领域呢?
GAN,即生成对抗网络,是一个生成模型,也是半监督和无监督学习模型,它可以在不需要大量标注数据的情况下学习深度表征。最大的特点就是提出了一种让两个深度网络对抗训练的方法。
目前机器学习按照数据集是否有标签可以分为三种,监督学习、半监督学习和无监督学习,发展最成熟,效果最好的目前还是监督学习的方法,但是在数据集数量要求更多更大的情况下,获取标签的成本也更加昂贵了,因此越来越多的研究人员都希望能够在无监督学习方面有更好的发展,而 GAN 的出现,一来它是不太需要很多标注数据,甚至可以不需要标签,二来它可以做到很多事情,目前对它的应用包括图像合成、图像编辑、风格迁移、图像超分辨率以及图像转换等。
比如字体的转换,在 zi2zi 这个项目中,给出了对中文文字的字体的变换,效果如下图所示,GAN 可以学习到不同字体,然后将其进行变换。

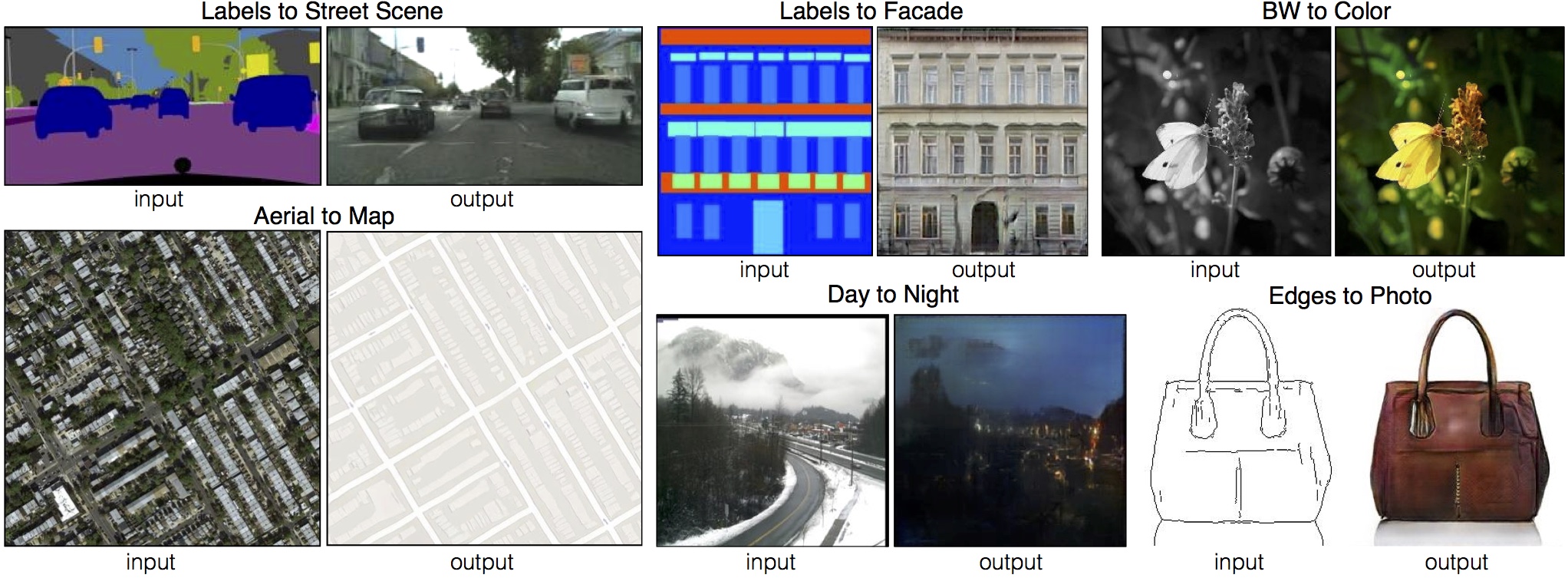
除了字体的学习,还有对图片的转换, pix2pix 就可以做到,其结果如下图所示,分割图变成真实照片,从黑白图变成彩色图,从线条画变成富含纹理、阴影和光泽的图等等,这些都是这个 pix2pixGAN 实现的结果。
CycleGAN 则可以做到风格迁移,其实现结果如下图所示,真实照片变成印象画,普通的马和斑马的互换,季节的变换等。

上述是 GAN 的一些应用例子,接下来会简单介绍 GAN 的原理以及其优缺点,当然也还有为啥等它提出两年后才开始有越来越多的 GAN 相关的论文发表。
1. 基本原理
GAN 的思想其实非常简单,就是生成器网络和判别器网络的彼此博弈。
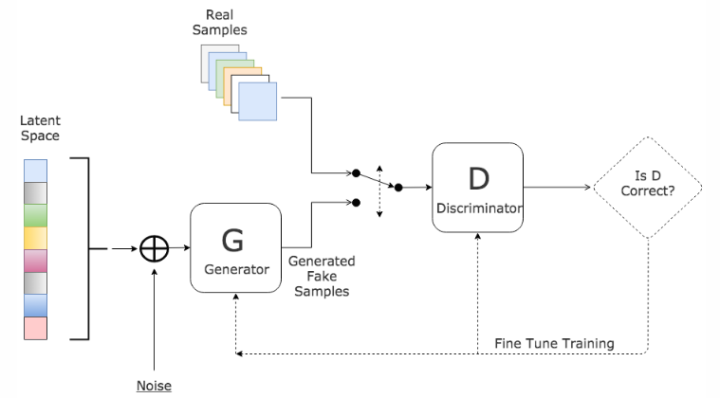
GAN 主要就是两个网络组成,生成器网络(Generator)和判别器网络(Discriminator),通过这两个网络的互相博弈,让生成器网络最终能够学习到输入数据的分布,这也就是 GAN 想达到的目的—学习输入数据的分布。其基本结构如下图所示,从下图可以更好理解G 和 D 的功能,分别为:
- D 是判别器,负责对输入的真实数据和由 G 生成的假数据进行判断,其输出是 0 和 1,即它本质上是一个二值分类器,目标就是对输入为真实数据输出是 1,对假数据的输入,输出是 0;
- G 是生成器,它接收的是一个随机噪声,并生成图像。
在训练的过程中,G 的目标是尽可能生成足够真实的数据去迷惑 D,而 D 就是要将 G 生成的图片都辨别出来,这样两者就是互相博弈,最终是要达到一个平衡,也就是纳什均衡。
2. 优点
(以下优点和缺点主要来自 Ian Goodfellow 在 Quora 上的回答,以及知乎上的回答)
- GAN 模型只用到了反向传播,而不需要马尔科夫链
- 训练时不需要对隐变量做推断
- 理论上,只要是可微分函数都可以用于构建 D 和 G ,因为能够与深度神经网络结合做深度生成式模型
- G 的参数更新不是直接来自数据样本,而是使用来自 D 的反向传播
- 相比其他生成模型(VAE、玻尔兹曼机),可以生成更好的生成样本
- GAN 是一种半监督学习模型,对训练集不需要太多有标签的数据;
- 没有必要遵循任何种类的因子分解去设计模型,所有的生成器和鉴别器都可以正常工作
3. 缺点
- 可解释性差,生成模型的分布
Pg(G)没有显式的表达 - 比较难训练, D 与 G 之间需要很好的同步,例如 D 更新 k 次而 G 更新一次
- 训练 GAN 需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,所以训练 GAN 相比 VAE 或者 PixelRNN 是不稳定的,但我认为在实践中它还是比训练玻尔兹曼机稳定的多.
- 它很难去学习生成离散的数据,就像文本
- 相比玻尔兹曼机,GANs 很难根据一个像素值去猜测另外一个像素值,GANs 天生就是做一件事的,那就是一次产生所有像素,你可以用 BiGAN 来修正这个特性,它能让你像使用玻尔兹曼机一样去使用 Gibbs 采样来猜测缺失值
- 训练不稳定,G 和 D 很难收敛;
- 训练还会遭遇梯度消失、模式崩溃的问题
- 缺乏比较有效的直接可观的评估模型生成效果的方法
3.1 为什么训练会出现梯度消失和模式奔溃
GAN 的本质就是 G 和 D 互相博弈并最终达到一个纳什平衡点,但这只是一个理想的情况,正常情况是容易出现一方强大另一方弱小,并且一旦这个关系形成,而没有及时找到方法平衡,那么就会出现问题了。而梯度消失和模式奔溃其实就是这种情况下的两个结果,分别对应 D 和 G 是强大的一方的结果。
首先对于梯度消失的情况是D 越好,G 的梯度消失越严重,因为 G 的梯度更新来自 D,而在训练初始阶段,G 的输入是随机生成的噪声,肯定不会生成很好的图片,D 会很容易就判断出来真假样本,也就是 D 的训练几乎没有损失,也就没有有效的梯度信息回传给 G 让 G 去优化自己。这样的现象叫做 gradient vanishing,梯度消失问题。
其次,对于模式奔溃(mode collapse)问题,主要就是 G 比较强,导致 D 不能很好区分出真实图片和 G 生成的假图片,而如果此时 G 其实还不能完全生成足够真实的图片的时候,但 D 却分辨不出来,并且给出了正确的评价,那么 G 就会认为这张图片是正确的,接下来就继续这么输出这张或者这些图片,然后 D 还是给出正确的评价,于是两者就是这么相互欺骗,这样 G 其实就只会输出固定的一些图片,导致的结果除了生成图片不够真实,还有就是多样性不足的问题。
更详细的解释可以参考 令人拍案叫绝的Wasserstein GAN,这篇文章更详细解释了原始 GAN 的问题,主要就是出现在 loss 函数上。
3.2 为什么GAN不适合处理文本数据
- 文本数据相比较图片数据来说是离散的,因为对于文本来说,通常需要将一个词映射为一个高维的向量,最终预测的输出是一个one-hot向量,假设 softmax 的输出是
(0.2, 0.3, 0.1,0.2,0.15,0.05),那么变为 onehot是(0,1,0,0,0,0),如果softmax输出是(0.2, 0.25, 0.2, 0.1,0.15,0.1 ),one-hot 仍然是(0, 1, 0, 0, 0, 0),所以对于生成器来说,G 输出了不同的结果, 但是 D 给出了同样的判别结果,并不能将梯度更新信息很好的传递到 G 中去,所以 D 最终输出的判别没有意义。 - GAN 的损失函数是 JS 散度,JS 散度不适合衡量不想交分布之间的距离。(WGAN 虽然使用 wassertein 距离代替了 JS 散度,但是在生成文本上能力还是有限,GAN 在生成文本上的应用有 seq-GAN,和强化学习结合的产物)
3.3 为什么GAN中的优化器不常用SGD
- SGD 容易震荡,容易使 GAN 的训练更加不稳定,
- GAN 的目的是在高维非凸的参数空间中找到纳什均衡点,GAN 的纳什均衡点是一个鞍点,但是 SGD 只会找到局部极小值,因为 SGD 解决的是一个寻找最小值的问题,但 GAN 是一个博弈问题。
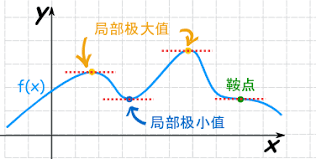
对于鞍点,来自百度百科的解释是:
鞍点(Saddle point)在微分方程中,沿着某一方向是稳定的,另一条方向是不稳定的奇点,叫做鞍点。在泛函中,既不是极大值点也不是极小值点的临界点,叫做鞍点。在矩阵中,一个数在所在行中是最大值,在所在列中是最小值,则被称为鞍点。在物理上要广泛一些,指在一个方向是极大值,另一个方向是极小值的点。
鞍点和局部极小值点、局部极大值点的区别如下图所示:
4. 训练的技巧
训练的技巧主要来自Tips and tricks to make GANs work。
1. 对输入进行规范化
- 将输入规范化到 -1 和 1 之间
- G 的输出层采用
Tanh激活函数
2. 采用修正的损失函数
在原始 GAN 论文中,损失函数 G 是要 $min (log(1-D))$, 但实际使用的时候是采用 $max(logD)$,作者给出的原因是前者会导致梯度消失问题。
但实际上,即便是作者提出的这种实际应用的损失函数也是存在问题,即模式奔溃的问题,在接下来提出的 GAN 相关的论文中,就有不少论文是针对这个问题进行改进的,如 WGAN 模型就提出一种新的损失函数。
3. 从球体上采样噪声
- 不要采用均匀分布来采样
- 从高斯分布中采样得到随机噪声
- 当进行插值操作的时候,从大圆进行该操作,而不要直接从点 A 到 点 B 直线操作,如下图所示
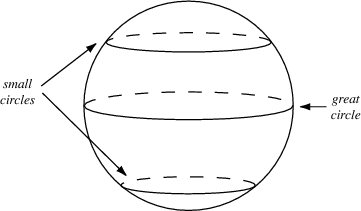
- 更多细节可以参考 Tom White’s 的论文 Sampling Generative Networks 以及代码 https://github.com/dribnet/plat
4. BatchNorm
- 采用 mini-batch BatchNorm,要保证每个 mini-batch 都是同样的真实图片或者是生成图片
- 不采用 BatchNorm 的时候,可以采用 instance normalization(对每个样本的规范化操作)
- 可以使用虚拟批量归一化(virtural batch normalization):开始训练之前预定义一个 batch R,对每一个新的 batch X,都使用 R+X 的级联来计算归一化参数
5. 避免稀疏的梯度:Relus、MaxPool
- 稀疏梯度会影响 GAN 的稳定性
- 在 G 和 D 中采用 LeakyReLU 代替 Relu 激活函数
- 对于下采样操作,可以采用平均池化(Average Pooling) 和 Conv2d+stride 的替代方案
- 对于上采样操作,可以使用 PixelShuffle(https://arxiv.org/abs/1609.05158), ConvTranspose2d + stride
6. 标签的使用
- 标签平滑。也就是如果有两个目标标签,假设真实图片标签是 1,生成图片标签是 0,那么对每个输入例子,如果是真实图片,采用 0.7 到 1.2 之间的一个随机数字来作为标签,而不是 1;一般是采用单边标签平滑
- 在训练 D 的时候,偶尔翻转标签
- 有标签数据就尽量使用标签
7. 使用 Adam 优化器
8. 尽早追踪失败的原因
- D 的 loss 变成 0,那么这就是训练失败了
- 检查规范的梯度:如果超过 100,那出问题了
- 如果训练正常,那么 D loss 有低方差并且随着时间降低
- 如果 g loss 稳定下降,那么它是用糟糕的生成样本欺骗了 D
9. 不要通过统计学来平衡 loss
10. 给输入添加噪声
- 给 D 的输入添加人为的噪声
- 给 G 的每层都添加高斯噪声
11. 对于 Conditional GANs 的离散变量
- 使用一个 Embedding 层
- 对输入图片添加一个额外的通道
- 保持 embedding 低维并通过上采样操作来匹配图像的通道大小
12 在 G 的训练和测试阶段使用 Dropouts
- 以 dropout 的形式提供噪声(50%的概率)
- 训练和测试阶段,在 G 的几层使用
- https://arxiv.org/pdf/1611.07004v1.pdf
参考文章:
- Goodfellow et al., “Generative Adversarial Networks”. ICLR 2014.
- GAN系列学习(1)——前生今世
- 干货 | 深入浅出 GAN·原理篇文字版(完整)
- 令人拍案叫绝的Wasserstein GAN
- 生成对抗网络(GAN)相比传统训练方法有什么优势?
- the-gan-zoo
- What-is-the-advantage-of-generative-adversarial-networks-compared-with-other-generative-models
- What-are-the-pros-and-cons-of-using-generative-adversarial-networks-a-type-of-neural-network-Could-they-be-applied-to-things-like-audio-waveform-via-RNN-Why-or-why-not
- Tips and tricks to make GANs work
注:配图来自网络和参考文章
以上就是本文的主要内容和总结,可以留言给出你对本文的建议和看法。
同时也欢迎关注我的微信公众号—机器学习与计算机视觉或者扫描下方的二维码,和我分享你的建议和看法,指正文章中可能存在的错误,大家一起交流,学习和进步!
